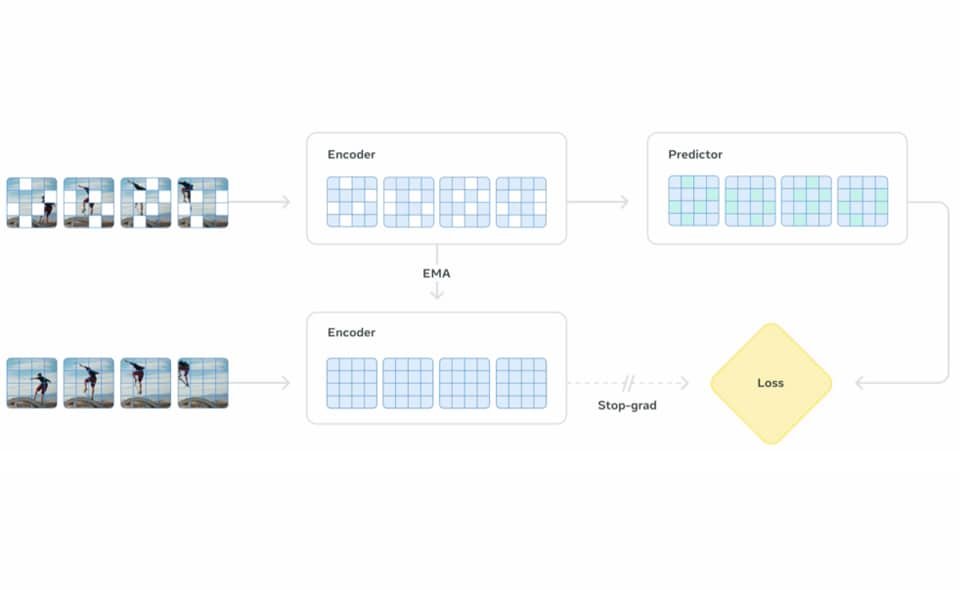
เทคโนโลยี & นวัตกรรมMeta เปิดตัวปัญญาประดิษฐ์ที่ “เข้าใจโลก” ใช้ควบคุมหุ่นยนต์ Oat Content1 ปี ago1 ปี ago1 mins Meta กำลังยกระดับศักยภาพของปัญญาประดิษฐ์จาก “การเรียนรู้ข้อมูล” ไปสู่ “การเข้าใจโลกจริง” ล่าสุดได้เปิดตัวโมเดล V-JEPA 2 (Video Joint Embedding Predictive Architecture 2) ซึ่งเป็น AI ที่สามารถรับรู้และทำนายผลในโลกกายภาพ ผ่านวิดีโอ โดยไม่จำเป็นต้องผ่านการฝึกเฉพาะทางในแต่ละสถานการณ์ จากวิดีโอสู่การตัดสินใจที่ชาญฉลาด V JEPA 2 ได้รับการฝึกด้วยวิดีโอความยาวกว่า 1 ล้านชั่วโมง โดยระบบจะรับอินพุตเป็นวิดีโอเหตุการณ์ทั่วไป จากนั้นพยายาม คาดการณ์เหตุการณ์ที่จะเกิดขึ้นต่อไป ซึ่งทำให้โมเดลสามารถเข้าใจบริบทในโลกจริง เช่น การเคลื่อนที่ของวัตถุ หรือปฏิกิริยาเชิงฟิสิกส์ แต่สิ่งที่น่าสนใจกว่านั้นคือ เมื่อเปลี่ยนมาฝึกเฉพาะด้าน การควบคุมหุ่นยนต์ ด้วยวิดีโอเพียง 62 ชั่วโมง V JEPA 2 ก็สามารถทำงานร่วมกับหุ่นยนต์ได้อย่างมีประสิทธิภาพ แม้ไม่เคย “เห็น” ตัวอย่างของงานนั้นมาก่อนเลย ไม่ได้ควบคุมโดยตรง... แต่เลือกการกระทำได้อย่างแม่นยำ ใส่ภาพของสถานะเริ่มต้นของหุ่นยนต์ใส่ภาพหรือเงื่อนไขของเป้าหมายป้อนตัวเลือกของการกระทำต่างๆ ระหว่างทางจากนั้น V JEPA 2 จะประเมินและ “เลือก” การกระทำที่เหมาะสมที่สุดเพื่อให้หุ่นยนต์บรรลุเป้าหมาย โดยความแม่นยำของโมเดลอยู่ที่ 65–80% ไม่มาแค่โมเดลเดียว แต่ Meta เปิดตัวชุดทดสอบ AI ในโลกจริงอีก 3 ชุด เพื่อทดสอบและผลักดันการพัฒนา AI ที่เข้าใจโลกกายภาพได้จริง Meta ยังปล่อยชุดข้อมูลสำคัญอีก 3 ชุดพร้อมกัน ได้แก่IntPhys 2 – สำหรับการประเมินว่าเหตุการณ์ในวิดีโอ “เป็นไปได้” หรือ “เป็นไปไม่ได้” ตามหลักฟิสิกส์MVPBench – สำหรับทดสอบ AI ในการประมวลผลวิดีโอพร้อมกับคำสั่ง/คำถามที่เป็นข้อความCausalVQA – ชุดคำถาม-คำตอบที่เน้นเรื่องเหตุและผลในวิดีโอ V JEPA 2 ไม่ได้เป็นเพียงการพัฒนาโมเดลรับภาพ แต่เป็นอีกก้าวสำคัญของปัญญาประดิษฐ์ที่ เข้าใจเหตุผลเชิงฟิสิกส์ และสามารถลงมือเลือกทางออกในสถานการณ์ใหม่ ๆ ได้โดยไม่ต้องพึ่งข้อมูลฝึกแบบเดิม นี่คือจุดเริ่มต้นของ AI ที่สามารถ “คิดและตัดสินใจ” ในโลกจริงได้อย่างเป็นธรรมชาติ และอาจกลายเป็นรากฐานของหุ่นยนต์อัจฉริยะในอนาคตอันใกล้ tags : ai.meta Facebook แนะแนวเรื่อง Previous: OpenAI เปิดตัว “o3-pro” บน ChatGPT แม่นยำกว่า ฉลาดขึ้นNext: Google เปิดตัวไลบรารีใหม่เอาไว้รันโมเดลภาษา Gemma3 ได้ทุกที่ ใส่ความเห็น ยกเลิกการตอบอีเมลของคุณจะไม่แสดงให้คนอื่นเห็น ช่องข้อมูลจำเป็นถูกทำเครื่องหมาย *ความเห็น * ชื่อ * อีเมล * เว็บไซต์
Google Home Speaker รุ่นใหม่เริ่มขายแล้ว! มาพร้อม Gemini for Home สั่งงานบ้านอัจฉริยะได้เป็นธรรมชาติ Oat Content12 ชั่วโมง ago12 ชั่วโมง ago
จีนสร้าง “สะพานสองชั้นยาวที่สุดในโลก” ช่วงกลางยาว 2,000 เมตร ตั้งอานเคเบิลสำเร็จ WaWaW Content14 ชั่วโมง ago14 ชั่วโมง ago
จีนผลิต “ซิลิคอน-28” บริสุทธิ์กว่า 99.99% ได้สำเร็จ เร่งเครื่องสู่ยุคชิปควอนตัมเต็มตัว Oat Content16 ชั่วโมง ago15 ชั่วโมง ago
จีนเปิดตัว WaveFly 5X “ยานบินเหนือผิวน้ำ” รุ่นแรกสำหรับบุคคล วิ่งได้ 80 กม. ต่อการชาร์จ Oat Content2 วัน ago2 วัน ago