











Google เดินหน้าปูทางให้โมเดลภาษาขนาดเล็กสามารถทำงานได้ “ทุกที่” ล่าสุดเปิดตัวโปรเจกต์ใหม่ชื่อว่า LiteRT-LM ซึ่งเป็นไลบรารีที่เขียนด้วย C++ ใช้สำหรับรันโมเดลภาษา (LLM) โดยเฉพาะ จะบนมือถือ แล็ปท็อป หรือเดสก์ท็อป ก็จัดได้หมด
แล้วมันต่างจากของเดิมยังไง?
ก่อนหน้านี้ Google มี TensorFlow Lite กับ MediaPipe GenAI ที่ช่วยให้โมเดล AI ทำงานบนอุปกรณ์ได้อยู่แล้ว แต่ LiteRT-LM ออกแบบมาเพื่อเน้นที่ “โมเดลภาษา” โดยเฉพาะ และกำหนดรูปแบบไฟล์โมเดลใหม่เลย เป็นนามสกุล .litertlm (อ่านว่า ไลท์อาร์ที-แอลเอ็ม) ตอนนี้มีโมเดลที่รองรับแล้วคือ
- Gemma3 1B
- Gemma3n E4B
และใช้งานได้แล้วบน CPU ทุกแพลตฟอร์ม ไม่ว่าจะเป็น Android, Windows, macOS หรือ Linux ส่วนเวอร์ชันที่รองรับ GPU กำลังจะตามมาเร็ว ๆ นี้
Run Gemma 3n on desktop (Mac, Win, Linux) and IoT with LiteRT-LM. This early preview is offered with a C++ API, and is fully open source and customizable. pic.twitter.com/rGYolgT1sy
— Google AI Developers (@googleaidevs) June 10, 2025
ทีม Google ทดสอบจริงบน
- MacBook Pro M3
- Samsung Galaxy S24 Ultra
ผลคือสามารถรัน Gemma3 1B ได้ที่ความเร็วระดับใช้งานได้จริงเลย อยู่ที่ประมาณ 44–67 โทเค็นต่อวินาที ส่วน Gemma3n ก็ทำได้ในระดับ “โอเค” ไม่ช้าเกินไป
ควบคุมได้ละเอียดขึ้น ไม่ใช่แค่สั่งแล้วรอผล
จุดเด่นของ LiteRT LM คือเปิดให้ ควบคุม LLM ได้ลึกกว่าเดิม เช่น แยกขั้นตอนการทำงานออกเป็น 2 ส่วน
- Prefill: ป้อนพรอมพ์เข้าไปก่อน ล็อกสถานะไว้ในโมเดล
- Decode: ค่อยสั่งให้โมเดลสร้างคำตอบออกมา
ซึ่ง Prefill จะเร็วกว่า Decode หลายเท่าตัว (6–60 เท่าเลยทีเดียว) นักพัฒนาสามารถใช้เทคนิคนี้เพื่อเร่งความเร็วเวลารันโมเดลซ้ำ ๆ ได้แบบเห็นผลจริง
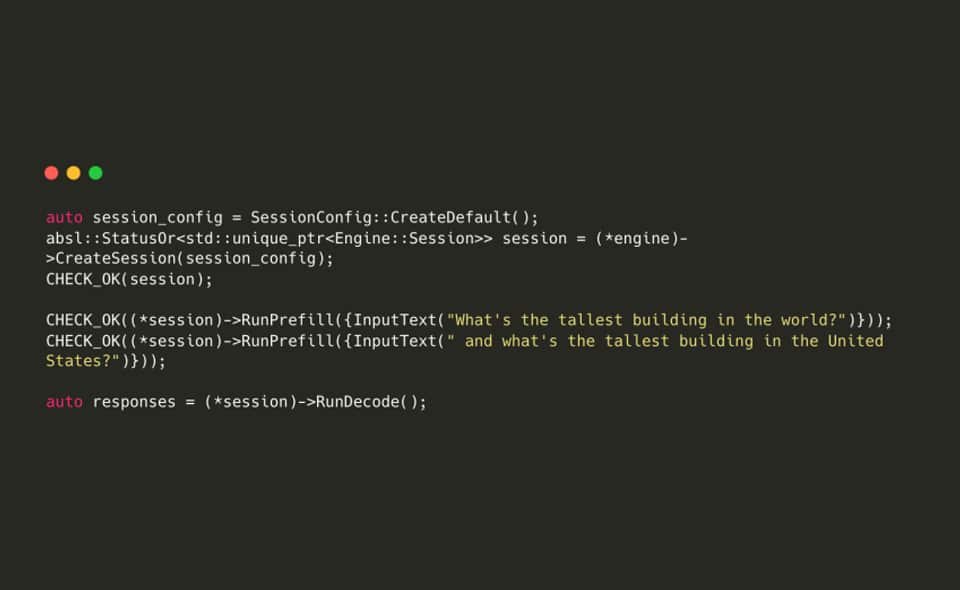
ที่มารูป : blognone
อนาคต MediaPipe จะย้ายมารวมกับ LiteRT-LM
ก่อนหน้านี้ Google มี MediaPipe GenAI ที่ทำงานคล้าย ๆ กัน แต่แผนในระยะยาวคือ Google จะพัฒนา LiteRT LM ให้เป็นโครงหลัก แล้วค่อยย้ายทุกอย่างจาก MediaPipe มาอยู่ที่นี่แทน เพื่อให้ทุกอย่างรวมศูนย์และทำงานง่ายขึ้น
tags : blognone, github



